
Начальный этап
Идем в любое Getting started соревнование (как уже упоминалось, автор начинал с House Prices: Advanced Regression Techniques), и начинаем создавать наши ноутбуки. Читаем паблик кернелы, копируем куски кода, процедуры, подходы, и т.д. и т.п. Прогоняем данные через пайплайн, сабмитим — смотрим на результат, улучшаем и так по кругу.
Примерный список того, что должно быть уже готовым и работающим на 100% перед переходом к следующему этапу:
- EDA. (статистики по датасету, боксплоты, разброс категорий, …)
- Data Cleaning. (пропуски через fillna, чистка категорий, объединение категорий)
-
Data preparation
- Общий (обработка категорий — label/ohe/frequency, проекция числовых на категории, трансформация числовых, бининг)
- Для регрессий (различное масштабирование)
-
Models
- Linear models (различные регрессии — ridge/logistic)
- Tree models (lgb)
- Feature selection
- Ensemble
«Подарок бога и эликсир жизни»
Одно из последних ярких литературных описаний курильни принадлежит Конан Дойлу, рассказавшему о притоне от лица доктора Ватсона в рассказе «Человек с рассеченной губой» 1891 года:
Символично, что за год до этого именно Конан Дойл, врач по образованию, короновал на страницах «Знака четырех» другой наркотик, заменивший опиум в качестве универсального лекарства. В первой сцене повести Шерлок Холмс распаковывает сафьяновый несессер, достает шприц и вкалывает себе семипроцентный раствор кокаина. Олицетворяющий автора Уотсон возмущается, но великий сыщик объясняет, что наркотик подстегивает мозг, пока он не занят очередным расследованием: «Возможно, вы правы, Уотсон, и наркотики вредят здоровью. Но зато я открыл, что они удивительно стимулируют умственную деятельность и проясняют сознание. Так что их побочным действием можно пренебречь».
Читатели и критики восприняли Холмса с восторгом — в газете Scotsman его даже назвали «Чарльзом Дарвином детективного мира». С одной стороны, зависимость героя не вписывалась в систему взглядов автора, с другой — именно кокаин, ставший чудом последних десятилетий викторианской эпохи, как нельзя лучше подходил эксцентричному и далекому от стандартов общества Шерлоку. Для Конан Дойла кокаин ознаменовал не возвращение к упадку и разложению опиумной эпохи, а триумф науки и технологий. Этот наркотик в отличие от расслаблявшего предшественника, наоборот, активизировал все способности человека и раскручивал их на максимум — такие качества сочетались с энтузиазмом и острым интеллектом самого Холмса.
Путь кокаина к сердцам британцев начался в 1884 году, когда молодой венский офтальмолог Карл Коллер выяснил, что капля слабого раствора этого наркотика лишает нервные окончания глаза чувствительности и избавляет от боли. Открытие мгновенно распространилось по Европе, вызвав восторг научного сообщества. За первые шесть месяцев 1885 года в Британском медицинском журнале было опубликовано 60 статей, посвященных кокаину. Врач и журналист Альфред Креспи назвал кокаин «открытием, которое пленит воображение рода человеческого», а колумнист Scotsman описал новый наркотик почти как дар свыше: «Христос — покровитель больниц и приютов, а кокаин — один из благословенных инструментов в деле избавления от боли».
Внезапная популярность кокаина объясняется тем, какие проблемы медикам того времени доставляла анестезия. К моменту появления нового наркотика анестетики вроде хлороформа использовали уже 40 лет, но все они имели побочные эффекты. Их главным недостатком являлось то, что правильную дозу было невероятно сложно рассчитать. Из-за этого усыпленные хлороформом пациенты регулярно не просыпались, а врачи нервничали из-за постоянного риска. В 1894-м в Британском медицинском журнале вышло открытое письмо доктора Джея Макнамары: «Статистика смертей из-за хлороформа поражает своими цифрами. Возможно, пришло время отказаться от этого смертельного средства и положить конец человеческим жертвам, которые еженедельно кладутся на алтарь?»
Открытие Коллера разрешило казавшуюся безвыходной ситуацию с анестезией — наркотик легко снимал боль, если его вводили подкожно или просто втирали в оперируемую часть тела. Под конец XIX века кокаин считали «главным чудом столетия и Ultima Thule медицины», «подарком бога и эликсиром жизни». Постепенно он занял в повседневной жизни британцев место, которое до этого занимал лауданум: его принимали от лихорадки, морской болезни, зубной боли, простуды и гриппа. Самый популярный викторианский татуировщик Сазерленд Макдональд колол раствор кокаина клиентам до начала работы, чтобы они не чувствовали боли при перенесении на кожу масштабных рисунков.
Наркотик использовали при первых пластических операциях, из-за чего журналист Hampshire Telegraph предположил, что «в новом столетии обрести новую личину будет так же просто, как новую шляпку». Восприятие наркотиков, как и любого другого тренда или феномена, зависит от контекста эпохи. Для современных людей кокаин означает угрозу, но викторианским людям он подарил надежду на прогресс, избавление от страданий и фантастические преобразования человеческого тела.
Бэкенды
Бэкенды — это то, из-за чего Keras стал известен и популярен (помимо прочих достоинств, которые мы разберем ниже). Keras позволяет использовать в качестве бэкенда разные другие фреймворки. При этом написанный вами код будет исполняться независимо от используемого бэкенда. Начиналась разработка, как мы уже говорили, с Theano, но со временем добавился Tensorflow. Сейчас Keras по умолчанию работает именно с ним, но если вы хотите использовать Theano, то есть два варианта, как это сделать:
- Отредактировать файл конфигурации keras.json, который лежит по пути (или в случае операционных систем семейства Windows). Нам нужно поле :
- Второй путь — это задать переменную окружения , например, так:
Стоит отметить, что сейчас ведется работа по написанию биндингов для CNTK от Microsoft, так что через некоторое время появится еще один доступный бэкенд. Следить за этим можно здесь.
Также существует MXNet Keras backend, который пока не обладает всей функциональностью, но если вы используете MXNet, вы можете обратить внимание на такую возможность. Еще существует интересный проект Keras.js, дающий возможность запускать натренированные модели Keras из браузера на машинах, где есть GPU
Еще существует интересный проект Keras.js, дающий возможность запускать натренированные модели Keras из браузера на машинах, где есть GPU.
Так что бэкенды Keras ширятся и со временем захватят мир! (Но это неточно.)
Машинное обучение
№7. Smile (Коммиты: 1019, Контрибьютеры: 21)
Statistical Machine Intelligence and Learning Engine или же просто Smile – является многообещающей современной библиотекой машинного обучения, в чем-то похожей на scikit-learn в Python. Он разработан на Java, но у него также есть API для Scala. Библиотека достаточно быстрая и производительная: эффективное использование памяти, большой набор алгоритмов машинного обучения для классификации, регрессии, NNS, выбора функций и т. д.
№8. Spark ML
Библиотека машинного обучения, которая работает из коробки в Apache Spark. Сам Spark написан на Scala и имеет соответствующее API для всех своих библиотек.
Spark ML – в отличие от Spark MLlib (более старой библиотеки), работает с датафрэймами. Также она дает возможность строить пайплайны различных преобразований на ваших данных. Это может рассматриваться как последовательность этапов, где каждый этап представляет собой либо Transformer, который преобразует один датафрейм в другой, либо Estimator, например, алгоритм машинного обучения, который обучается на датафрейме.
№9. DeepLearning.scala (Коммиты: 1647, Контрибьютеры: 14)
DeepLearning.scala – это альтернативный инструмент машинного обучения, который позволяет строить модели deep learning. Библиотека использует математические формулы для создания сложных динамических нейронных сетей посредством комбинации объектно-ориентированного и функционального программирования. Она использует широкий спектр типов, а также классы аппликативных типов. Последнее позволяет начинать несколько вычислений одновременно, что повышает производительность.
№10. Summing Bird (Коммиты: 1772, Контрибьютеры: 31)
Summingbird – это фреймворк обработки данных, который позволяет использовать batch и real-time MapReduce-вычисления. Основным катализатором для разработки языка стали разработчики Twitter, которые часто занимались написанием одного и того же кода дважды: сначала для батчевой обработки, затем еще раз для стриминга.
Summingbird использует и генерирует два типа данных: потоки (бесконечные последовательности кортежей) и снэпшоты, которые в определенный момент времени считаются полным состоянием набора данных. Наконец, Summingbird предоставляет платформу для Storm, Scalding и движок для вычислений в памяти для целей тестирования.
№11. PredictionIO (Коммиты: 4343, Контрибьютеры: 125)
Стоит также упомянуть сервис машинного обучения для создания и развертывания прогностических механизмов, называемых PredictionIO. Он построен на Apache Spark MLlib и HBase и даже был оценен на Github как самый популярный продукт машинного обучения на основе Apache Spark. Он позволяет вам легко и эффективно создавать, оценивать и развертывать сервисы, реализовывать свои собственные модели машинного обучения и включать их в свой сервис.
Необычный экстерьер здания
При первом взгляде на это минималистическое здание создается впечатление, что каким-то чудесным образом вы оказались в далеком будущем. Идеально правильные очертания, обилие стекла и холодного металла, серо-стальной цвет направляют потоки мыслей к такому загадочному и невероятно притягательному космосу. Даже не верится, что перед вами жилой дом, в котором смеются дети, собираются компании, и все это происходит именно сейчас, а не через сто или тысячу лет.
Вокруг резиденции возведена бетонная ограда, выдержанная в общем стиле – никаких изгибов и украшений. Монолитная стена заканчивается, и изумленному взору открывается металлическая конструкция, как бы нависающая над головами проходящих людей. Черный, причудливо изогнутый металл окантовывает выступы здания и как-то незаметно «просачивается» внутрь помещения, необъяснимым образом объединяя внешнее и внутреннее пространство.
Ярким привлекающим внимание акцентом экстерьера является огромный аквариум, встроенный в основание первого этажа

Экзотические рыбы привлекают внимание своим ярким окрасом, а ночью, благодаря встроенной подсветке, кажется, что маленький кусочек океана со всеми своими обитателями переместился прямо в этот дом
RAWGraphs
RAWGraphs
Сильные стороны бесплатной версии
- Диаграммы в RAWGraphs очень просто создавать, для работы с системой не нужно даже регистрировать учётную запись.
- Система поддерживает различные форматы входных данных — TSV, CSV, DSV, JSON и Excel-файлы(.xls, .xlsx).
- По сведениям RAWGraphs обработка данных производится исключительно средствами браузера. Платформа не занимается серверной обработкой или хранением данных. Никто из тех, кто не имеет отношения к данным, не сможет их просматривать, модифицировать или копировать.
- RAWGraphs — это система, поддающаяся расширению. Например, добавлять в неё новые диаграммы можно, обладая базовыми знаниями D3.js.
Слабые стороны бесплатной версии
- Диаграммы, создаваемые в RAWGraphs, иногда выглядят слишком простыми. У пользователей системы есть не особенно много механизмов для подстройки их под свои нужды.
- Визуализации данных не являются интерактивными.
@newlibrarians
Околобиблиотечный блог Библиотеки им. Д. С. Лихачева г. Санкт-Петербурга. Эстетика библиотечного дела, возведенная в культ! Тонко, изящно и иногда смешно.
Фишка Instagram Библиотеки им. Д. С. Лихачева СПбГБУ «ЦБС Выборгского района» не только стильное оформление постов, но и интересные рубрики!

Рубрики – это разделение постов в профиле Инстаграма по темам и видам. Рубрики решают несколько задач:
- Баланс контента: продуманные рубрики не дают заскучать пользователям. Сегодня забавная шутка, дальше – скрины лучших комментариев, в выходные – викторины и игры.
- Основа контент-плана: рубрики помогают спланировать посты и потом отслеживать их эффективность. Какая-та рубрика может «не зайти» аудитории, какая-то – понравится.
- Удобство ведения профиля: когда спланированы темы на несколько недель вперед, то профиль становится вести проще.
Страх перед опиумом превратил курильни в главный викторианский миф

Отвращение к опиумным курильням в творчестве Диккенса смешалось с любопытством и болезненным интересом к экзотическому феномену. В полухудожественной статье «Лазарь поедающий лотос» 1866 года писатель сначала рисует пропитанный ксенофобией образ китайского опиумного наркомана, который вызывал лишь отторжение и неприязнь: нищий Лазарь одет в штаны из протертой парусины и изорванную куртку, у него неестественно высокие скулы, узкие глазки и грязный хвостик. «Мы с вами оглядываемся в поисках полицейского, чтобы тот увел его домой», — усиливает эффект Диккенс.
Мнение героя меняется, когда, проследив за Лазарем, он сам оказывается в опиумной курильне и лучше узнает ее обитателей: «Остальные были по-своему достойными людьми, чьей главной слабостью оставался опиум и которые редко имели проблемы с полицией». Неизвестно, как часто сам Диккенс бывал в курильнях, но образ опиумного смрада в подвальном помещении, полном ослабевших и потерянных людей, настолько его впечатлил, что писатель сделал эту тему одной из главных в своем последнем незаконченном романе «Тайна Эдвина Друда» 1870 года.
В нем зависимость символизирует двойную жизнь антагониста, регента хора в городском соборе Джона Джаспера. Однако в первом же абзаце Диккенс описывает наркотическую галлюцинацию слишком красочно и реалистично для моралиста, которому отвратительна одна мысль о курильнях:
Диккенс — яркий пример дуалистичного отношения к восточному следу в английской культуре. С одной стороны, он придает ему отчетливый негативный оттенок и изображает пристрастие к опиуму как падение на дно общества, с другой — образ курильни явно завораживает и привлекает его. К тому же он слишком подробно описывает механику курения опиума и устройство притона, чтобы знать о нем с чьих-то слов. Из-за загадочного и неоднозначного статуса в викторианской культуре опиумные курильни превратились чуть ли не в главный миф эпохи — их масштабы преувеличивали, а их предназначению придавали зловещий оттенок.
Читая Диккенса, Оскара Уайльда и Артура Конан Дойла в XXI веке легко представить, что подобные заведения попадались чуть ли не на каждом углу за пределами неприступного Сити, хотя даже на пике популярности опиумные курильни оставались редким и прозаичным феноменом. Китайская диаспора в Лондоне не разрасталась больше нескольких сотен человек — они женились на англичанках и открывали притоны в доках, где их в основном посещали моряки. После месяцев плавания те не только удовлетворяли экзотическую зависимость, но и находили проституток. Эти заброшенные бараки превратились в эпицентр криминальной жизни Англии лишь с подачи писателей и журналистов, раздувших китайскую угрозу.
На самом деле все известные примеры в художественной литературе списаны лишь с двух курилен, существовавших в реальности. «Этими небольшими предприятиями управляла горстка китайских иммигрантов и их английских подружек, — историк Мэттью Свит. — Такова реальность, которую заволокло облако литературного вымысла». В первой половине XIX века курильни регулярно посещали аристократы, искавшие острых ощущений и разнообразия среди светской рутины. Именно их восприятие подарило современной поп-культуре образ курильни как чего-то загадочного и экзотического, хотя с 1860-х годов притоны, как и опиум вообще, постепенно уступили место другим развлечениям и наркотикам.
Будущее библиотек в России
С 1 декабря 2018 года по 20 января 2019 года для школьников 7-14 лет проходит всероссийский online конкурс «Моя библиотека будущего»
Цель проекта – привлечь внимание учащихся к библиотекам и их возможностям, повысить научную грамотность детей
Учащимся предлагается рассказать, как, по их мнению, должны выглядеть современные библиотеки и их пространства: читальные залы, зоны отдыха и так далее. Участники могут также разработать визуальную модель библиотеки (с помощью графических редакторов или рисунков) и приложить ее к работе. Конкурс проводится на сайте globallab.org.
Я, конечно, не подхожу для участия в проекте по возрасту. Но как должна выглядеть современная библиотека (даже не библиотека будущего, а библиотека наших дней), я теперь знаю. Такие библиотеки, как в Хельсинки, действительно являются центрами притяжения людей. Будем надеяться, что дождемся подобного в России.
Scikit Learn
Scikit Learn, представленный миру как проект Google Summer of Code, представляет собой надежную библиотеку машинного обучения для Python. Он включает в себя алгоритмы ML, такие как SVM, random forests, k-means кластеризацию, спектральную кластеризацию, сдвиг среднего значения, перекрестную проверку и многие другие. Даже NumPy, SciPy и связанные с ними научные операции поддерживаются Scikit Learn, при этом Scikit Learn является частью SciPy Stack.
Когда использовать? Scikit-learn предоставляет ряд контролируемых и неконтролируемых алгоритмов обучения через согласованный интерфейс в Python. Scikit learn будет вашим руководством для того, чтобы модели контролируемого обучения, такие как Naive Bayes, группировали непомеченные данные, такие как KMeans.
Что можно делать с помощью Scikit Learn?
1. Классификация: обнаружение спама, распознавание изображений;
2. Кластеризация: воздействия лекарственных препаратов, цена акций;
3. Регрессия: сегментация клиентов, группировка результатов эксперимента;
4. Уменьшение размерности: визуализация, повышенная эффективность;
5. Выбор модели: повышенная точность благодаря настройке параметров;
6. Предварительная обработка: подготовка входных данных в виде текста для обработки с помощью алгоритмов машинного обучения.
Scikit Learn фокусируется на моделировании данных; не манипулировании данными. Для обобщения и манипуляции у нас есть NumPy и Pandas.
Как создать библиотеку компонентов
Сделайте пустой файл, который станет библиотекой, и наполняйте его компонентами. Вначале нарисуйте составные части компонента. Затем выделите их и щёлкните Create Component в верхней панели.
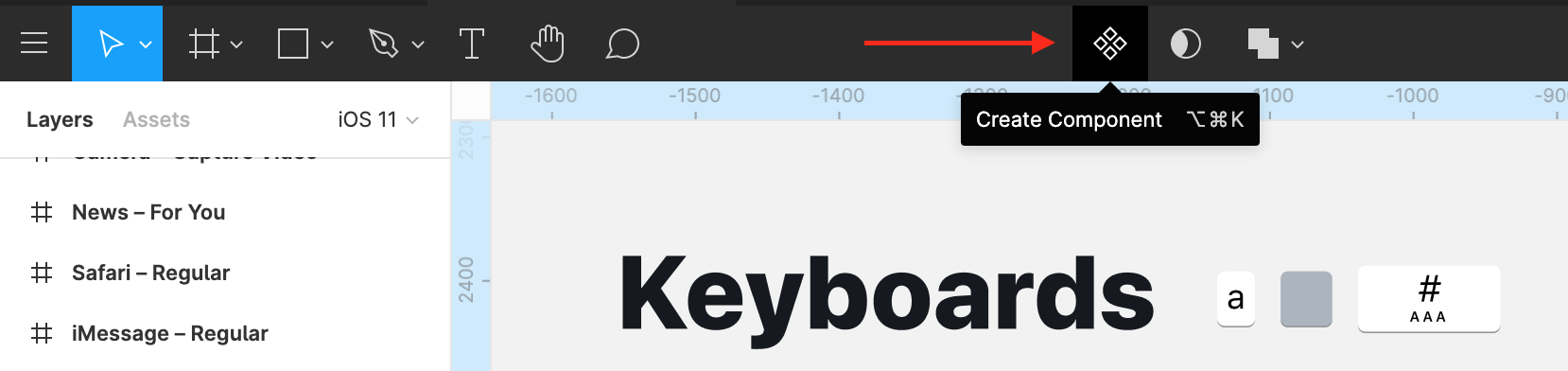
Чтобы новую библиотеку можно было использовать в проектах, её нужно опубликовать. Сделайте это на вкладке Assets, кликнув иконку-книгу и нажав Publish.
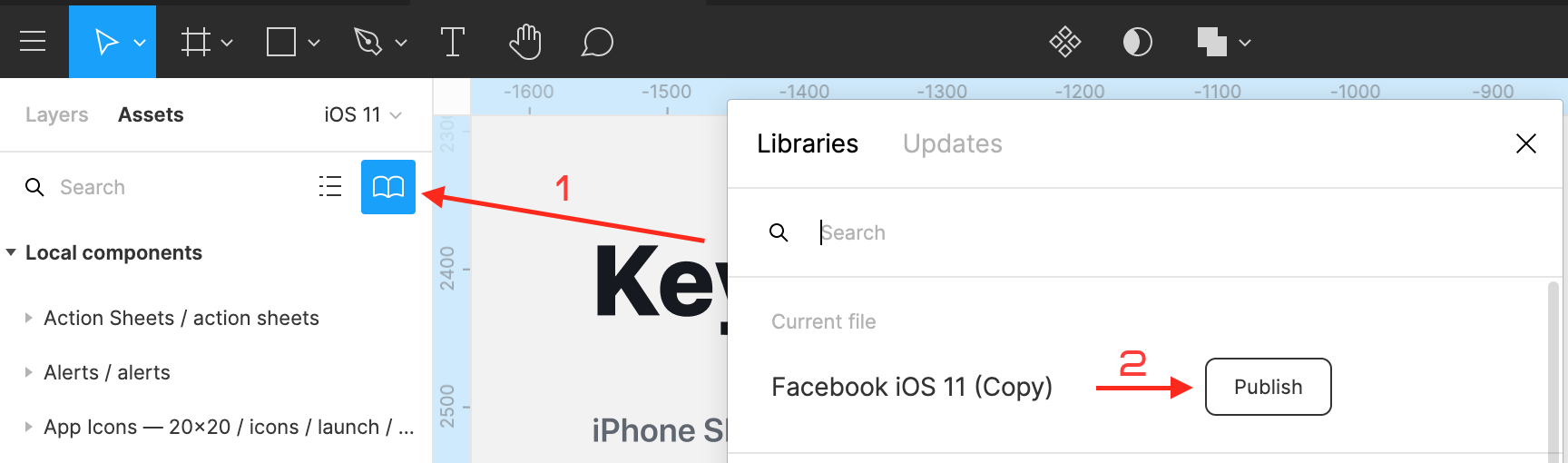
С библиотеками проще работать, если соблюдать несколько правил:
- Добавлять всё, что встретится больше двух раз. Интерактивные элементы, иконки, слайдеры, тапбары, аватары пользователей, лэйауты экранов, меню и так далее.
- Начинать с меньшего. По принципам атомарного дизайна вначале создают наименьшие неделимые элементы: например, заголовки и параграфы, иконки, чек-боксы. Позже они станут частью других компонентов.
- Вкладывать состояния. Изображения для элемента в разных состояниях часто располагают одно над другим. Например, кнопка с наведённым курсором и нажатая кнопка. Чтобы переключиться, включают и отключают видимость каждого из них.
- Использовать фреймы как папки. Создать фрейм можно с помощью символа решётки в верхней панели. Это прямоугольник, напоминающий окно в операционной системе.
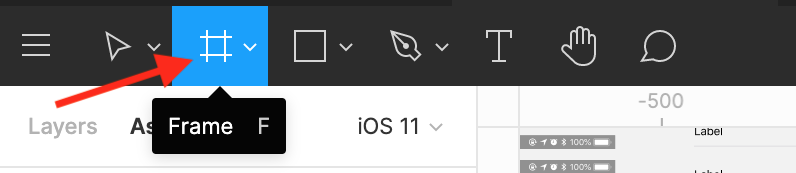
Фрейм называют как категорию элементов. Допустим, «Уведомления» — все уведомления помещают в него. Визуально так проще ориентироваться, но самое главное — в раскрывающемся списке компонентов появится одноимённый пункт.
Внутренние помещения
Попав внутрь дома, понимаешь, что настоящее искусство — это не только театр, поэзия или картины. Это еще и умение из обычного здания сотворить нечто, способное полностью завладеть разумом и сердцем. Ничего лишнего – прямые, стремящиеся ввысь линии, строгая мебель, своеобразные светильники. Весь внутренний дизайн является органичным продолжением экстерьера.
Переступив порог дома, мы попадаем в прихожую.

Никакого декора, только металл и стекло. Огромное окно-стена является общим для первого и второго этажа. Здесь же начинается и лестница, по которой можно попасть на верхние этажи. Стремительные очертания немного смягчены перфорированными полосами металла и небольшими светильниками, вмонтированными под лестничными маршами.

Кухонный комплекс, включающий столовую, гостиную и, непосредственно, кухню, расположен на открытой площадке первого этажа здания. Между комнатами нет четких границ, они являются плавным продолжением друг друга.

Мебель, выполненная в теплых тонах, немного сглаживает резкость интерьера из стали и бетона. Преобладающие цвета: маренго (серый, приближенный к черному), светло-бежевый и темно-стальной. В качестве акцентных пятен выступают ярко-оранжевые диванные подушки и строгие вазы с цветами.

Взгляд также привлекают небольшие трехмерные скульптурные композиции, выполненные в футуристическом стиле.
С удобного дивана в гостиной открывается прекрасный вид на большой бассейн с прозрачно-голубой водой. На верхних этажах расположены четыре спальни и две детские комнаты. Минимальное количество мебели, окна-стены от пола до потолка и строгая цветовая палитра, использованная в интерьере, создают ощущения необычайного простора. Полное единение с природой достигается также благодаря балкону, выходящему из главной спальни, с прекрасным видом на сад.

Архитектурный ансамбль включает в себя также помещения для игр, просторную гардеробную и несколько помещений бытового назначения.


В загородном доме имеется также огромная комната, предназначенная для приема гостей и приятного времяпрепровождения всей семьей. Здесь есть все необходимое для максимального расслабления: плазменный телевизор, камин, возле которого можно расположиться на удобных креслах, открытая жаровня и небольшая барная стойка, где можно изредка побаловать себя бокалом волшебного вина.
 Метки к статье:
Метки к статье:
Предисловие или лирическое отступление о библиотеках для глубокого обучения
В настоящее время разработаны десятки библиотек для работы с нейронными сетями, все они, подчас существенно, различаются в реализации, но можно выявить два основных подхода: императивный и символьный.
Давайте посмотрим на примере, чем они различаются. Предположим, что мы хотим вычислить простое выражение
Вот так оно выглядело бы в императивном изложении на языке python:
Интерпретатор исполняет код построчно, сохраняя результаты в переменных , , и .
Та же программа в символьной парадигме выглядела бы так:
Существенное различие заключается в том, что когда мы объявляем , исполнения не происходит, мы лишь задали граф вычислений, который затем скомпилировали и наконец выполнили.
Оба подхода имеют свои достоинства и недостатки. В первую очередь, императивные программы гибче, нагляднее и проще в отладке. Мы можем использовать все богатства используемого языка программирования, например, циклы и ветвления, выводить промежуточные результаты в отладочных целях. Такая гибкость достигается, в первую очередь, малыми ограничениями, накладываемыми на интерпретатор, который должен быть готов к любому последующему использованию переменных.
С другой стороны, символьная парадигма накладывает больше ограничений, но вычисления получаются более эффективными, как по памяти, так и по скорости исполнения: на этапе компиляции можно применить ряд оптимизаций, выявить неиспользуемые переменные, выполнить часть вычислений, переиспользуя память и так далее. Отличительная черта символьных программ — отдельные этапы объявления графа, компиляции и выполнения.
Мы останавливаемся на этом так подробно, потому что императивная парадигма знакома большинству программистов, в то время как символьная может показаться непривычной, и Theano, как раз, явный пример символьного фреймворка.
Тем, кому хочется разобраться в этом вопросе подробнее, рекомендую почитать соответствующий раздел документации к MXNet (об этой библиотеке мы еще напишем отдельный пост), но ключевой момент для понимания дальнейшего текста заключается в том, что программируя на Theano, мы пишем на python программу, которую потом скомпилируем и выполним.
Но довольно теории, давайте разбираться с Theano на примерах.
Гуанахуато
- Как добраться из Мехико: c северного автовокзала (Autobuses del Norte) на автобусе компании Primera Plus, направление Гуанахуато. В пути около пяти часов. Стоимость билета 24$.
- Где остановиться: отели в Гуанахуато.
- Музыка города: Buena Vista Social Club–Chan Chan.
Перемещаемся в город-калейдоскоп Гуанахуато! Это лоскутное одеяло из цветных домиков раскинулось на холмистой местности, так что хорошая физическая форма для прогулок не повредит. Кстати, город иногда называют вертикальным из-за подъёмов, лестниц и глубоких тоннелей между домами.
Гуанахуато как будто раскрасили всеми возможными цветами. Фото: SL-Photography / Shutterstock.com
Лабиринты ярких улиц кружат тебя в танце, ты делаешь миллион фотографий, сто тысяч ступенек вокруг, проходил ли ты уже здесь? Идеальная головоломка!
Если тебе недостаточно насладиться просто прогулкой по этому городу, то маленький Гуанахуато удивит тебя большим количеством достопримечательностей, связанных с искусством, здесь даже автобусы выглядят необычно.

Вертикальный Гуанахуато. Фото: Shutterstock.com
Что посмотреть
- В городе три исторических театра: Театр Сервантес, или Teatro Cervantes Guanajuato — здесь обожают Дон Кихота и Санчо Пансо, даже установили памятник (билеты от 5$), Театр Хуарес (Teatro Juarez) — работает и как музей, но есть возможность сходить на спектакль (билеты от 1,7$), и Театр Принсипаль (Teatro Principal) — здание с потрясающей красоты архитектурой (билеты от 4$).
- Продолжая тему Дон Кихота, загляни в любопытное место — Иконографический музей Дон Кихота (Museo Iconografico del Quijote, билеты от 1,5$). Он наполнен портретами рыцаря в различных техниках. Зрелище самобытное, будто попадаешь в целую вселенную, где существуют тысячи разных Дон Кихотов, у каждого разная судьба и взгляд на мир. Удивительно!
- Ну и конечно, ты не пройдешь мимо главного открыточного вида Гуанахуато — солнечной, нарядной и дерзкой Базилики Parroquia de Basílica Colegiata de Nuestra Señora de Guanajuato. Уф, главное выговорить. Вход бесплатный.
Базилика с длинным названием, которую ты точно не пропустишь. Фото: eskystudio / Shutterstock.com
Идем в бой
Выбираем любое понравившееся соревнование и … начинаем ![]()
- Прогоняем данные через наш сформированный пайплайн и сабмитим результат
- Хватаемся за голову, психуем, успокаиваемся… и продолжаем…
- Читаем все кернелы на предмет использованных техник и подходов
- Читаем все обсуждения на форуме
- Переделываем/дополняем пайплайны новыми техниками
- Переходим к п. 1
Помним — наша цель на данном этапе — получить опыт! Наполнить наши пайплайны рабочими подходами и методами, заполнить наши модули работающим кодом. Не заморачиваемся на медалях — вернее как, здорово, если получится сразу занять свое место на лидерборде, но если нет — не паримся. Мы пришли сюда не на пять минут, медали и плашки никуда не уйдут.
Вот соревнование закончено, вы где-то там, казалось бы все — хватаемся за следующее?
НЕТ!
Что вы делаете дальше:
- Ждете пять дней. Не читайте форум, забудьте про Kaggle на это время. Дайте мозгу отдохнуть и размылить взгляд.
- Возвращаетесь к соревнованию. За эти пять дней по правилам хорошего тона все топы выложат описание своих решений — в постах на форуме, в виде кернелов, в виде гитхабовских репозиториев.
И тут начинается ваш персональный АД!
- Вы берете несколько листов формата А4, на каждом пишете название модуля из вышеописанного фреймворка (EDA/ Preparation/ Model/ Ensemble/ Feature selection/ Hyperparameters search/ …)
- Последовательно читаете все решения, выписываете на соответствующие листочки новые для вас техники, методы, подходы.
И самое страшное:
- Последовательно по каждому модулю пишете (подсматриваете) реализацию этих подходов и методов, расширяя ваш пайплайн и библиотеки.
- В режиме пост-сабмита прогоняете данные через ваш обновленный пайплайн до тех пор, пока у вас не будет решения в золотую зону ну или пока не кончится терпение и нервы.
И вот только после этого переходим к следующему соревнованию.
Нет, я не охренел. Да, можно и проще. Вам решать.
Почему ждать 5 дней, а не читать сразу, ведь на форуме можно позадавать вопросы? На данном этапе (на мой взгляд) лучше читать уже сформированные треды с обсуждениями решений, вопросы, которые у вас могут возникнуть — либо кто-то уже задаст, либо их лучше пока вообще не задавать, а искать ответ самим )
Зачем все это делать именно так? Ну, еще раз — задача данного этапа наработать базу решений, методов и подходов. Боевую рабочую базу. Чтобы в следующем соревновании вы не тратили время, а сразу сказали — ага, тут может зайти mean target encoding, и кстати, у меня и правильный код для этого через фолды в фолдах есть. Или о! помнится тогда заходил ансамбль через scipy.optimize, а кстати у меня и код уже готов.
Как-то так…
Примечание
Все дальнейшее описание будет основано на работе с табличными и текстовыми данными. Картинки, которых сейчас очень много на Kaggle — это отдельная тема с отдельными фреймворками. На базовом уровне хорошо уметь их обрабатывать, хотя бы для того, чтобы прогнать через что-то типа ResNet/VGG и вытащить фичи, но более глубокая и тонкая работа с ними — это отдельная и очень обширная тема, не рассматриваемая в рамках данной статьи.
Автор честно признается, что не очень умеет в картинки. Единственная попытка приобщиться к прекрасному была в соревновании Camera Identification, в котором, кстати, наши команды с тегом взорвали весь лидерборд до такой степени, что админам Kaggle пришлось зайти к нам в слак в гости, убедиться, что все в рамках правил — и успокоить коммьюнити. Так вот, в этом соревновании мне досталось почетное серебро с 46-м местом, а когда прочитал описание топовых решений от наших коллег, то понял, что забраться выше и не светит — там у них применяется реально черная магия с аугментацией, добросом 300Гб данных, жертвоприношениями и прочим.
В общем если хотите начинать с картинок — то вам нужны другие фреймворки и другие руководства.
SciPy
Библиотека SciPy является одним из ключевых пакетов, которые составляют стек SciPy. Теперь есть разница между SciPy Stack и библиотекой SciPy. SciPy основывается на объекте массива NumPy и является частью стека, который включает в себя такие инструменты, как Matplotlib, Pandas и SymPy с дополнительными инструментами.
Библиотека SciPy содержит модули для эффективных математических процедур, таких как линейная алгебра, интерполяция, оптимизация, интеграция и статистика. Основной функционал библиотеки SciPy построен на NumPy и его массивах.
Когда использовать? SciPy использует массивы в качестве базовой структуры данных. Он имеет различные модули для выполнения общих задач научного программирования, таких как линейная алгебра, интеграция, матанализ, обыкновенные дифференциальные уравнения и обработка сигналов.
Что можно делать с помощью SciPy?
1. Математические, научные, инженерные вычисления;
2. Процедуры численной интеграции и оптимизации;
3. Поиск минимумов и максимумов функций;
4. Вычисление интегралов функции;
5. Поддержка специальных функций;
6. Работа с генетическими алгоритмами;
7. Решение обыкновенных дифференциальных уравнений.
Египет, Александрия, Библиотека Александрина или Новая Александрийская библиотека

Уничтожение библиотеки в Александрии отмечено в летописях истории как один из самых кощунственных культурных актов всех времен. Но хотя 700 000 текстов, которые были потеряны, никогда не могут быть восстановлены, в 2002 году Египет открыл новую библиотеку Александрина, превратив ее в глобальный культурный центр с пожертвованиями со всего мира.

Библиотека, которая называет себя «центром обучения, терпимости, диалога и взаимопонимания», проводит художественные выставки, семинары, имеет четыре музея и постоянно пополняет коллекцию книг, количество которой насчитывает до пяти миллионов экземпляров. Экскурсии проводятся каждые 15 минут на арабском, английском, французском и испанском языках.
Городская библиотека Штутгарта

Одна из лучших библиотек Германии расположилась в Штутгарте. Внешняя архитектура здания, представляющего собой обычный куб, достаточно проста и вряд ли вызовет интерес, но вот его внутренний дизайн – это гимн современности и инновациям. Построенное в 2011 году книгохранилище располагается на 9 этажах, каждый из которых посвящен отдельной тематике, например, искусству или детской литературе.
Здесь вы не найдете традиционных читальных залов со скрипучей мебелью, но приятно удивитесь футуристическим диванам с подушками. Ну а специально оборудованные кабины для пользования интернетом и прослушивания музыки только дополняют новаторский антураж помещения.
Необычный дизайн внутри сооружения призван не столько поражать воображение, сколько обращать внимание посетителей исключительно на книги. Тем не менее профессиональные издания заслуженно оценили архитектуру городского хранилища Штутгарта и включили его в список 25 самых красивых библиотек в мире
Infogram
Infogram
Сильные стороны бесплатной версии
- Infogram, в отличие от других инструментов, поддерживает анимации, позволяющие изменять масштаб объектов, организовывать их перемещение, отражение, появление и исчезновение, прокрутку.
- В визуализации можно добавлять собственные элементы, изображения и фигуры.
Слабые стороны бесплатной версии
- В бесплатной версии можно создать не более 10 проектов, в каждом из которых может содержаться до 5 страниц.
- Infogram поддерживает более 550 типов карт. Но в бесплатной версии доступно лишь 13 типов.
- В бесплатной версии нельзя создавать проекты, закрытые от посторонних.
- Нельзя организовывать подключение к источникам данных и работать с данными, изменяющимися в режиме реального времени.



